进程和线程
多线程
Python的标准库提供了两个模块:_thread和threading,其中_thread是低级模块,threading是高级模块,对_thread进行了封装,绝大多数情况下,只是使用高级模块thread。任何进程默认会启动一个线程,将其称之为主线程,由主线程启动的新线程称之为子线程。
启动一个线程需要把一个函数传入并创建Thread实例,然后调用start()执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import time,threading
def loop():
print('thread %s is running...'%threading.current_thread().name)
n=0
while n<5:
n=n+1
print('thread %s >>>%s'% (threading.current_thread().name,n))
time.sleep(1)
print('thread %s ended.'% threading.current_thread().name)
print('thread %s is running...'%threading.current_thread().name)
t=threading.Thread(target=loop,name='LoopThread')
t.start()
t.join()
print('thread %s ended.'% threading.current_thread().name)
thread MainThread is running...
thread LoopThread is running...
thread LoopThread >>>1
thread LoopThread >>>2
thread LoopThread >>>3
thread LoopThread >>>4
thread LoopThread >>>5
thread LoopThread ended.
thread MainThread ended.
|
Lock
多进程中,同一个变量各自有一份拷贝存在于每个进程中,多个进程之间的变量之间互不影响。
多线程中,所有变量都由所有线程共享,所以任何一个变量都可以被任何线程修改,即容易发生像在sql数据库中的读脏数据的情况。若要避免线程读脏数据的情况,就要给变量上锁。
可以通过threading.Lock()来创建一个锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import time,threading
balance=0
def change_it(n):
global balance
balance=balance+n
balance=balance-n
lock=threading.Lock()
def run_thread(n):
for i in range(100000):
lock.acquire()
try:
change_it(n)
finally:
lock.release()
t1=threading.Thread(target=run_thread,args=(5,))
t2=threading.Thread(target=run_thread,args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
0
|
当多个线程同时执行lock.acquire()时,只有一个线程能成功获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。获得锁的线程用完后一定要释放锁,否则其他等待的线程将永远等下去。
多核CPU
一个死循环线程会100%占用一个CPU。若有两个死循环线程,在多核CPU中会占用200%的CPU,即两个CPU核心。若想把n核CPU的核心全部跑满,就必须启动n个死循环线程。
但在6核CPU中运行python启动6个死循环线程,CPU占用率也就仅有25%。死循环线程代码如下:
1
2
3
4
5
6
7
8
| import threading,multiprocessing
def loop():
x=0
while True:
x=x^1
for i in range(multiprocessing.cpu_count()):
t=threading.Thread(target=loop)
t.start()
|
GIL锁
这是因为python解释器执行代码时,有一个GIL锁(Global
Interoreter
Lock),任何python线程执行前,必须先获得GIL锁,然后每执行100条字节码,解释器就自动释放GIL锁。这个GIL全局锁实际上给所有线程的执行代码都上了锁。因此多线程在python中只能交替执行,即使有100个线程跑在100核CPU上,也只能用到1个核。
因此在python中可以使用多线程,却不能够有效地利用多核。python虽然不能实现多线程并发,但可以通过多线程实现多核任务。多个python进程有各自独立的GIL锁,互不影响。
ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用局部变量比使用全局变量好。而全局变量的每次修改都要加锁,因此可以考虑用一个全局dict存放所有对象,然后以thread自身作为key来获得线程对应的对象,而在ThreadLocal中可以自动做这件事:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import threading
local_school=threading.local()
def process_student():
std=local_school.student
print('Hello,%s (in %s)'%(std,threading.current_thread().name))
def process_thread(name):
local_school.student=name
process_student()
t1=threading.Thread(target=process_thread,args=('Alice',),name='Thread-A')
t2=threading.Thread(target=process_thread,args=('Bob',),name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
Hello,Alice (in Thread-A)
Hello,Bob (in Thread-B)
|
可以理解为全局变量local_school是一个dict,其不但可以用local_school.student,还可以绑定其他变量。
ThreadLocal最常用在为每个线程绑定一个数据库连接、HTTP请求、用户身份信息等。
进程 vs 线程
要实现多任务通常会设计Master-Worker模式,Master复制分配任务,Worker负责执行任务,故在多任务环境下,通常是一个Master,多个Worker。
用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
用多线程实现Master-Worker,主线程就是Master,其他进程就是Worker。
多进程模式最大的优点是稳定性高。一个子进程崩溃了不会影响主进程核其他进程。其缺点是创建进程的开销大,占用系统资源较多,且操作系统同时运行的进程数也有限。
多线程模式通常比多进程快一点,其缺点是任何一个线程挂掉都可能直接造成整个进程崩溃。
线程切换
操作系统在切换进程或线程时,需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后把新任务的执行环境准备好(恢复上次的寄存器状态、切换内存页等),才能开始执行。
计算密集型 vs IO密集型
把任务分为计算密集型和IO密集型,并以此来考虑是否采用多任务。
计算密集型任务的特点是进行大量的计算,消耗CPU资源。要最高效的利用CPU,计算密集型任务同时进行的数量应当等于CPU的核数。python做计算密集型任务的运行效率很低,故最好是用C语言编写计算密集型任务。
IO密集型任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成。对于IO密集型任务,在一定限度内的任务最多,CPU效率越高。
异步IO
若充分利用操作系统提供的异步IO支持,就能用单线程模型来执行多任务,这种全新的模型称为事件驱动模型。对于python来说,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。
分布式进程
在线程和进程中,应当优先选择进程。因为进程更稳定,而且进程可以分布到多台机器上,而线程最多只能分布到同一台机器的多个CPU上。
python的multiprocessing模块不但支持多进程,其中的managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。
若有一个通过Queue通信的多进程程序在同一台机器上运行,现在要把发送任务的进程和处理任务的进程分布到两台机器上。原有的Queue可以继续用,通过managers模块把Queue通过网络暴露出去,其他机器的进程就可以访问Queue了。其实现如下:
服务器端Master的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import random,time,queue
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support
task_queue = queue.Queue()
result_queue = queue.Queue()
class QueueManager(BaseManager):
pass
def return_task_queue():
global task_queue
return task_queue
def return_result_queue():
global result_queue
return result_queue
def test():
QueueManager.register('get_task_queue',callable=return_task_queue)
QueueManager.register('get_result_queue',callable=return_result_queue)
manager = QueueManager(address=('127.0.0.1',5000),authkey=b'abc')
manager.start()
print('start server master')
task = manager.get_task_queue()
result = manager.get_result_queue()
for i in range(10):
n = random.randint(0,10000)
print('put task %d...' % n)
task.put(n)
print('try get results...')
for i in range(10):
r = result.get(timeout=10)
print('result:%s' % r)
manager.shutdown()
print('master exit')
if __name__ == '__main__':
freeze_support()
test()
|
在另一个文件里写非服务端Worker的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import time,sys,queue
from multiprocessing.managers import BaseManager
class QueueManager(BaseManager):
pass
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
server_addr = '127.0.0.1'
print('connect to server %s...'% server_addr)
m = QueueManager(address=(server_addr,5000),authkey=b'abc')
m.connect()
task = m.get_task_queue()
result = m.get_result_queue()
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...'% (n,n))
r = '%d * %d = %d' % (n,n,n*n)
time.sleep(1)
result.put(r)
except queue.Empty:
print('task queue is empty')
print('worker exit')
|
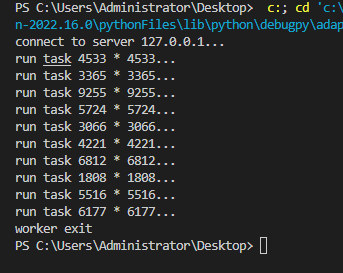
先运行服务端Marker的代码,再运行非服务端Worker的代码,运行结果如下:
服务端Marker的运行结果如下图:
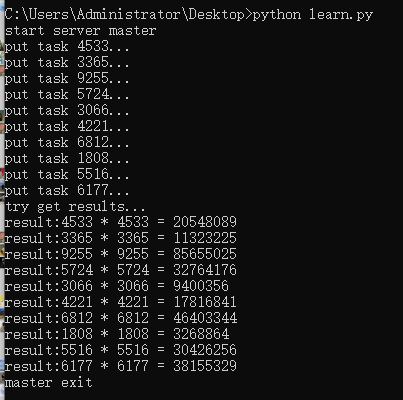
非服务端Worker的运行结果如下图: