PostgreSQL命令
由于Pgsql数据库的命令在运行时会自动转换为小写英文字母,故命令语句也可以用小写字母编写。
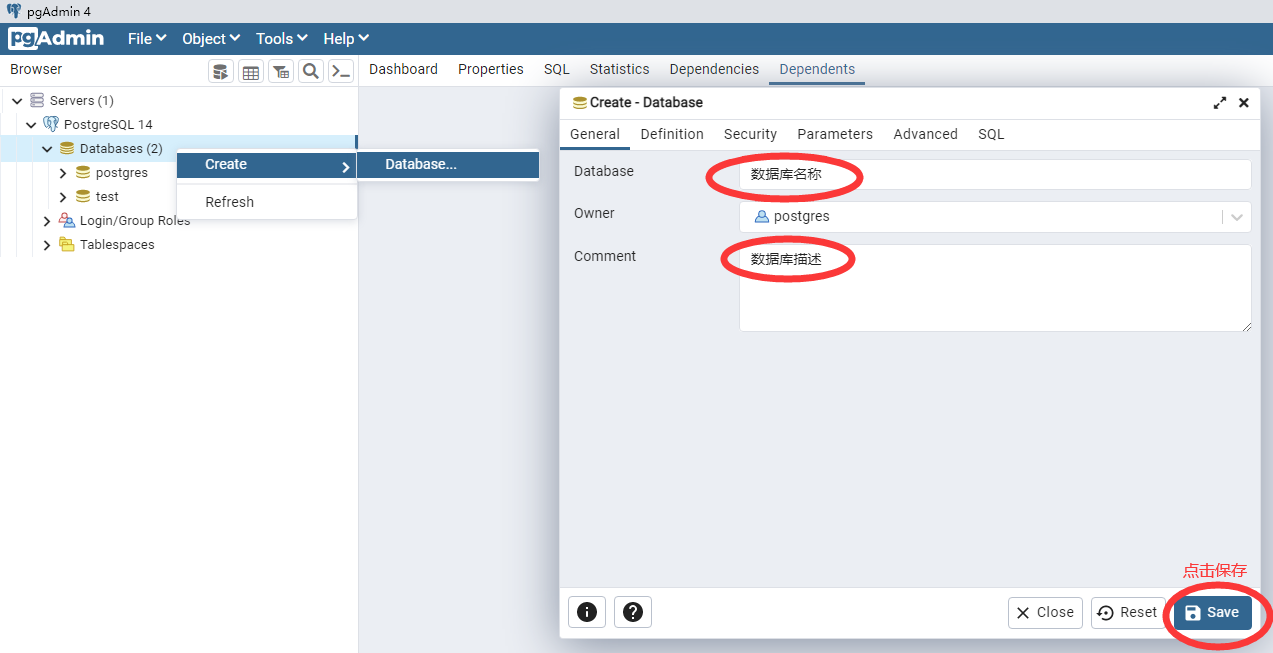
使用pgAdmin工具创建数据库
右键点击batabases,选择弹出的数据库的菜单。
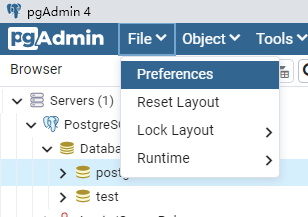
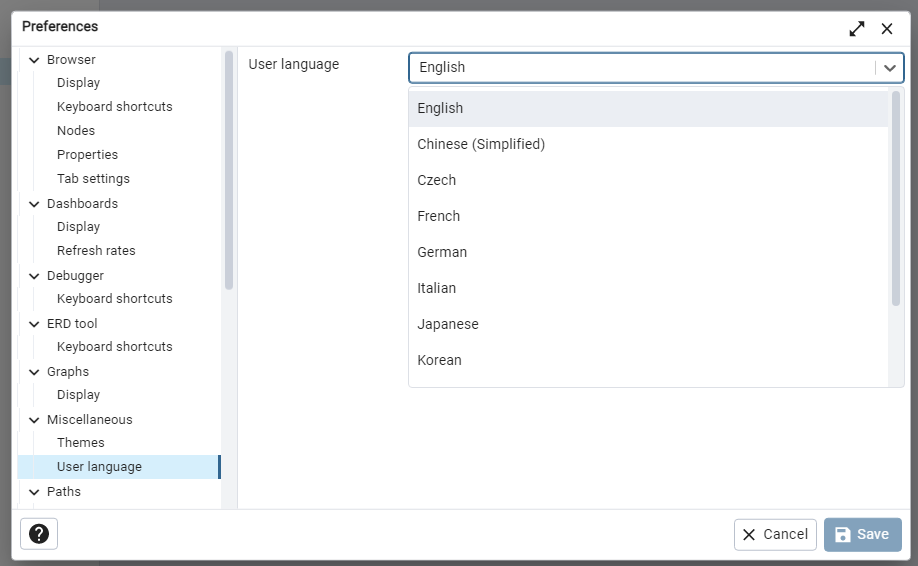
pgAdmin工具界面语言设成中文
左键点击File,弹出的Preferences。
选择左下角的User
language,点击右上角的箭头,选择Chinese(Simplified),点击Save保存。在弹出的Refresh
required窗口中点击Refresh保存即可。
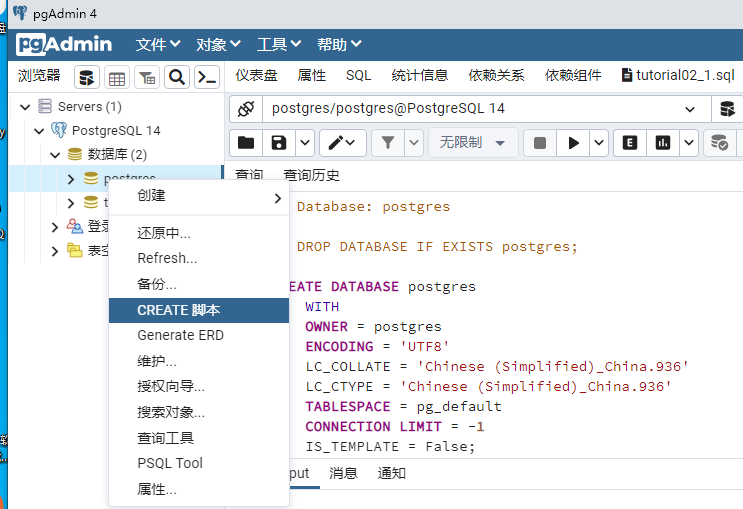
pgAdmin创建SQL脚本
在已经创建好的数据库名称中右键点击,选择CREATE
脚本,即可创建SQL脚本。可以在SQL脚本里编写PgSQL语句。
注意:SQL脚本中尽量不要直接点击运行代码。 这样在创建过一次表后,直接点击运行代码时会再次运行建表的语句,会报表格已存在的错。通常是选中需要运行的代码块后再点击执行按钮。 数据库只运行选中的代码,这样不会重复执行先前写好的代码,若没有选中任何代码,则默认为选中全部。
PgSQL创建数据库
1 2 3 4 5 6 7 8 9 10 11 12 create database postgres with owner= postgres encoding= 'UTF8' lc_collate= 'Chinese (Simplified)_China.936' lc_ctype= 'Chinese (Simplified)_China.936' tablespace= pg_default connection limit= -1 is_template= false ;
PgSQL的CRUD语句
create建表
使用create语句创建表:
1 2 3 4 5 6 7 8 9 create table rpt_tutorial( id serial primary key not null , name text not null , age int not null , datetime date not null );
create创建复合类型
使用create语句创建复合类型:
1 2 create type profession as (profession char (50 ));
创建复合类型后,可实现在表中自定义字段名称,其格式为:属性名 复合类型名 条件约束
insert插入数据
使用insert语句查询数据:
1 2 insert into rpt_tutorial(name,age,datetime,prof)values ('Zhangsan' ,30 ,'2022-10-14' ,'(teacher)' );
read读数据
使用select语句查询数据:
1 2 3 select * from rpt_tutorial;select name from rpt_tutorial where age>= 30 ;
update更新数据
使用update…set语句更新数据:
1 2 update rpt_tutorial set datetime= '2022-10-17' where datetime= '2022-10-14' ;
delete&drop删除数据
使用delete或drop语句删除数据:
1 2 3 4 5 6 7 8 9 10 delete from rpt_tutorialdrop table rpt_tutorialdrop type professiontruncate table rpt_tutorial restart identity ;
使用python进行PgSQL数据库连接
Psycopy是针对python的Postgres数据库的适配模块,安装psycopg2可以整合python和Postgres。可在cmd中输入命令进行安装:
导入psycopg2模块,并进行sql操作,其语句格式如下。
1 2 3 4 5 6 7 8 9 conn=psycopg2.connect(database="数据库名" ,user="数据库用户名" ,password="数据库密码" ,host="127.0.0.1" ,port="5432" ) print ("Opened database successfully" )cur=conn.cursor() cur.execute(''' sql操作语句 );''' )conn.commit() cur.close() conn.close()
使用python将csv文本的数据导入导出至pqsql
方法一:
使用psycopg2模块中的copy语句操作文本,由于csv文件默认以逗号分隔单元格,故导入导出时要注意加上或减去逗号:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 with open (resourcefilenames,'r' ,encoding='utf-8' ) as f: next (f) cur.copy_from(f,targettablename,sep=',' ,) write_head=True with open (targetfilenames,'w' ,encoding='utf-8' ) as f: columns=['id' ,'name' ,'age' ,'datetime' ] if write_head: s='' for k in columns: s+=k+',' s=s[:-1 ] f.write(s+'\n' ) write_head=False cur.copy_to(f,targettablename,sep=',' ,columns=columns) print ("Export csv successfully" )
方法二:
运用xlrd、xlwt模块导入导出数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import xlrdworkbook = xlrd.open_workbook(filename='C:/文件名' ) table = workbook.sheet_by_name(sheet_name='sheet表名' ) rows = table.nrows cols = table.ncols for row in range (rows): for col in range (cols): value = table.cell_value(row, col) print ('第{}行{}列的数据为:{}' .format (row, col, value)) import xlwtworkbook = xlwt.Workbook(encoding = 'utf-8' ) worksheet = workbook.add_sheet('text2' ) for row in range (rows): for col in range (cols): value = table.cell_value(row, col) worksheet.write(row, col, value) workbook.save('text2.csv' ) def outdata (data,file,sheetname ): work_book=xlwt.Workbook(encoding='utf-8' ) sheet=work_book.add_sheet(sheetname) sheet.write(0 ,0 ,'id' ) sheet.write(0 ,1 ,'name' ) sheet.write(0 ,2 ,'age' ) sheet.write(0 ,3 ,'datetime' ) for i in range (len (data)): for j in range (len (data[i])): sheet.write(i+1 ,j,'%s' % data[i][j]) work_book.save(file) print ("Data output successfully" ) outdata(rows,targetfilenames,'test' )
方法三:
运用csv模块导入导出数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import csvfrom re import Adef readfile (): f = open ('文件名' , 'r' ) csv_reader = csv.reader(f) a=[] for row_data in csv_reader: a.append(row_data) print (a) f.close() return a a=readfile() csvFile3 = open ('新文件名' ,'w' ,encoding='utf-8' ,newline='' ) writer2 = csv.DictWriter(csvFile3,fieldnames=['属性名' ]) key=a[0 ] for t in range (len (key)): writer2 = csv.writer(csvFile3) writer2.writerow(a[t]) csvFile3.close()